FuriosaAI’s Software Stack#
FuriosaAI offers a streamlined software stack that enables the FuriosaAI NPU to be used across various applications and environments. Here, we outline the software stack provided by FuriosaAI, explaining the roles of each component, along with guidelines and tutorials. The following diagram shows the software stack provided by FuriosaAI.
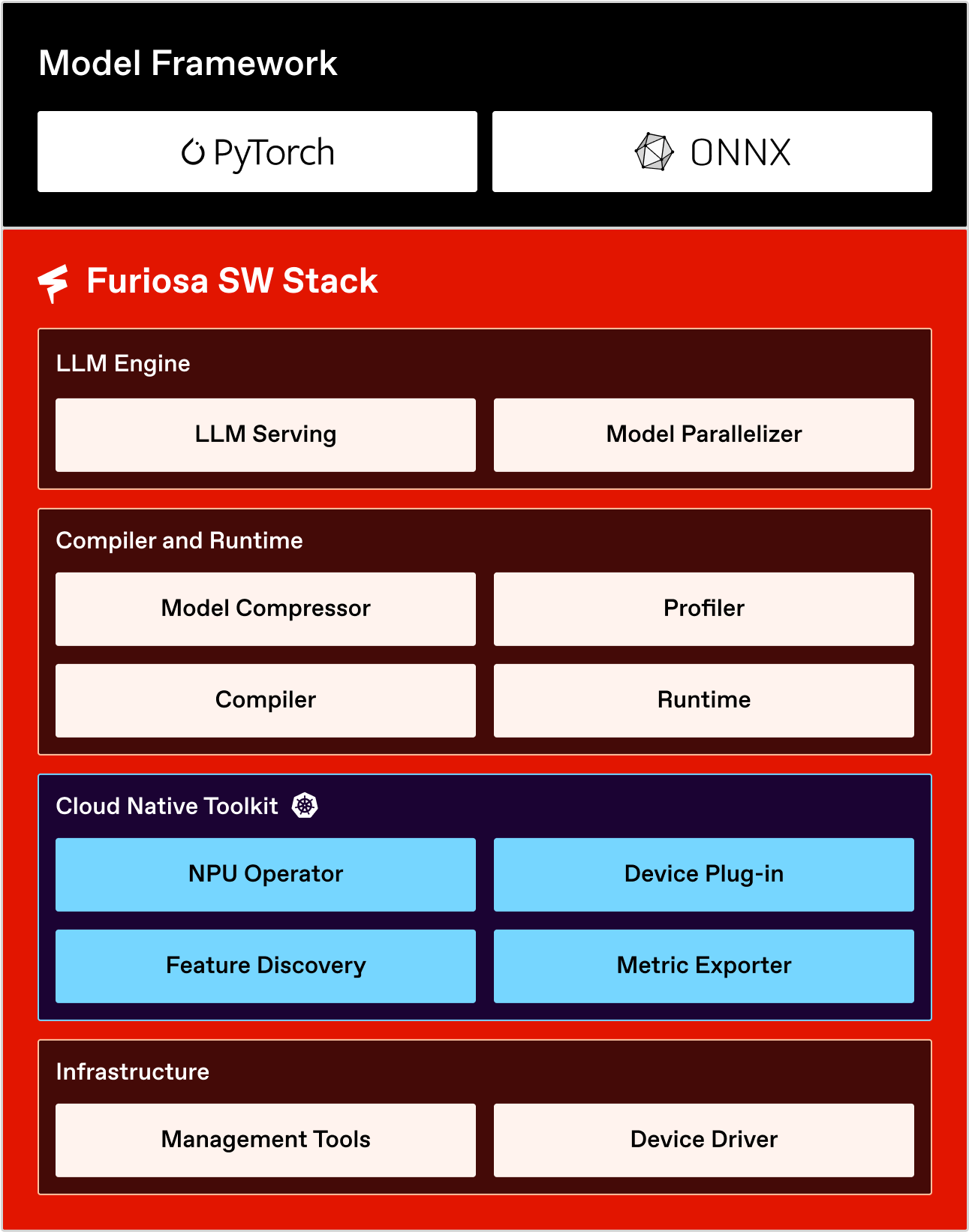
Kernel Driver, Firmware, and PE Runtime#
The kernel device driver enables the Linux operating system to recognize NPU devices and expose them as Linux device files. The firmware runs on the NPU and provides low-level APIs to the PE Runtime (PERT) that runs on the Processing Element (PE). PERT is responsible for communicating with the host’s runtime, as well as scheduling and managing the resources of PEs to execute NPU tasks.
Furiosa Compiler#
The Furiosa Compiler optimizes model graphs and generates executable programs for the NPU. It performs several optimizations, including graph-level optimizations, operator fusion, optimization of memory allocations, scheduling, and optimization of cross-layer data movements. A single model can be compiled into multiple executables, depending on the model’s architecture and application requirements.
When using FuriosaAI’s backend for torch.compile() (FuriosaBackend), or
the furiosa-llm package, the Furiosa Compiler is used transparently to
generate NPU executables.
Furiosa Runtime#
The Runtime loads the executables generated by the Furiosa compiler and runs them on the NPU. The Runtime is responsible for scheduling NPU programs and allocating memory on both the NPUs and the host RAM. Additionally, the Runtime supports the use of multiple NPUs and provides a unified entry point for running models across multiple NPUs seamlessly.
Furiosa Model Compressor (Quantizer)#
The Furiosa Model Compressor is a toolkit for model calibration and quantization. Model quantization is a powerful technique to reduce memory usage, computation cost, inference latency, and power consumption. The Furiosa Model Compressor provides post-training quantization methods, such as:
BF16 (W16A16)
INT8 Weight-Only (W8A16) (Planned)
FP8 (W8A8)
INT8 SmoothQuant (W8A8) (Planned)
INT4 Weight-Only (W4A16 AWQ / GPTQ) (Planned)
Furiosa-LLM#
Furiosa-LLM is a high-performance inference engine for LLM models, such as Llama and GPT-J. The key features of Furiosa-LLM include:
vLLM-compatible API, for seamless integration with vLLM-based workflows;
PagedAttention, for optimized memory usage for attention computation;
Continuous batching, improving throughput by dynamically grouping inference requests;
Hugging Face Hub support, simplifying access to pre-trained models;
OpenAI-compatible API server, enabling easy deployment using familiar APIs.
For more information, please refer to the Furiosa-LLM section.
Kubernetes Support#
Kubernetes, an open-source platform for managing containerized applications and services, is widely adopted by organizations for its powerful capabilities in deploying, scaling, and automating containerized workloads. The FuriosaAI software stack offers native integration with Kubernetes, enabling seamless deployment and management of AI applications within Kubernetes environments. FuriosaAI’s device plugin enables Kubernetes clusters to recognize FuriosaAI’s NPUs and schedule them for workloads that require them. This integration simplifies the deployment of AI workloads with FuriosaAI NPUs, ensuring efficient resource utilization and scalability.
For more information about Kubernetes support, please refer to the Cloud Native Toolkit section.