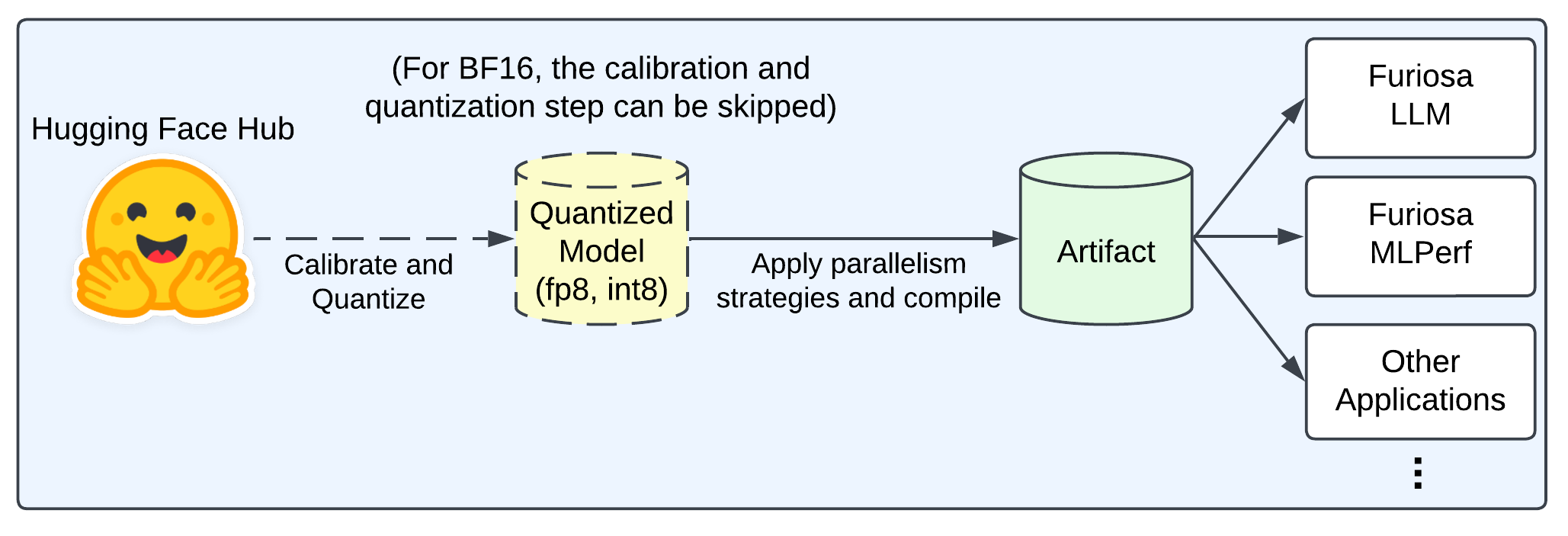
Model Preparation Workflow#
This document describes how to prepare a model to be served by Furiosa LLM. At a high level, the workflow consists of the following four steps:
Loading a model from Hugging Face Hub or a local disk
Calibrating the model and exporting the quantized model to a checkpoint
Building a model artifact
Deploying the model
Note
The latest release 2025.1.0 always requires the calibration and quantization steps for all models. The 2025.2 release will allow BF16 models to run on Furiosa LLM without the calibration and quantization steps. The 2nd step will be required only for INT8, FP8, and INT4 models.
Prerequisites#
Please ensure you meet the prerequisites before starting the model preparation workflow:
A system with the prerequisites installed (see Installing Prerequisites)
An installation of Furiosa LLM
Sufficient storage space for model weights, e.g., about 100 GB for the Llama 3.1 70B model
Loading a Model from Hugging Face Hub#
The Hugging Face Hub is a platform with over 900k models and 200k datasets which are open source
and publicly available. You can load a model from the Hugging Face Hub using the
furiosa_llm.optimum library. The QuantizerForCausalLM class provides a simple API to load a
model from the Hugging Face Hub and a quantize() method to calibrate and quantize the model.
QuantizerForCausalLM is a subclass of AutoModelForCausalLM,
so it finds automatically the model class from the Hugging Face model id in the same way as
AutoModelForCausalLM.
from furiosa_llm.optimum import QuantizerForCausalLM
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
quantizer = QuantizerForCausalLM.from_pretrained(model_id)
Quantizing a Model#
Quantization is a popular technique to reduce the required computational and memory resources for inference while preserving the accuracy of your model by mapping the high precision space of activations, weights, and KV cache to lower precision INT8, FP8, or INT4 space.
Currently, Furiosa LLM provides the PTQ (Post Training Quantization) technique to quantize a model.
To quantize a model, you need to calibrate the model with a calibration dataset and export the
quantized model to a checkpoint. The create_data_loader function creates a dataloader for
calibration by specifying the tokenizer, dataset name or path, the dataset split, the number of
samples, and the maximum sample length.
Tip
create_data_loader is based on the datasets library,
which provides easy access to datasets for audio, computer vision, and
natural language processing (NLP) tasks.
Learn more on the
datasets documentation
and explore the datasets at https://huggingface.co/datasets.
The QuantizerForCausalLM class provides a quantize() method to quantize
text-generation models.
The first argument of QuantizerForCausalLM is the model id of Hugging Face
Hub or the path to the model artifact.
The quantize() method takes the quantized model, a data loader, and a
quantization configuration as arguments.
Here is an example of quantizing a model:
from furiosa_llm.optimum.dataset_utils import create_data_loader
from furiosa_llm.optimum import QuantizerForCausalLM, QuantizationConfig
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
# Create a dataloader for calibration
dataloader = create_data_loader(
tokenizer=model_id,
dataset_name_or_path="mit-han-lab/pile-val-backup",
dataset_split="validation",
num_samples=5, # Increase this number for better calibration
max_sample_length=1024,
)
quantized_model = "./quantized_model"
# Load a pre-trained model from Hugging Face model hub
quantizer = QuantizerForCausalLM.from_pretrained(model_id)
# Calibrate, quantize the model, and save the quantized model
quantizer.quantize(quantized_model, dataloader, QuantizationConfig.w_f8_a_f8_kv_f8())
QuantizationConfig.w_f8_a_f8_kv_f8() is a quantization configuration
that quantizes the weights, activations, and KV cache to 8-bit floats (FP8).
The quantized model is stored to the save_dir directory.
Building a Model Artifact#
The next step is to build a model artifact, which is a set of files required to run the model on the Furiosa LLM engine. A model artifact includes model weights, configuration files, compiled NPU binary files, and other necessary metadata.
Once a model artifact is built, it can be deployed to any host with a Furiosa NPU and Furiosa LLM installed without further work.
You can create a model artifact using either the ArtifactBuilder API
or the furiosa-llm build command.
Here is an example using the ArtifactBuilder API.
from furiosa_llm.artifact.builder import ArtifactBuilder
quantized_model = "./quantized_model"
compiled_model = "./Output-Llama-3.1-8B-Instruct"
builder = ArtifactBuilder(
quantized_model,
tensor_parallel_size=4,
max_seq_len_to_capture=1024, # Maximum sequence length covered by LLM engine
)
builder.build(compiled_model)
The ArtifactBuilder class provides various options to build a model artifact.
The options include the set of devices, parallelism degrees, prefill buckets,
decode buckets, etc. You can find more details about the arguments in the
ArtifactBuilder section.
Alternatively, you can use the furiosa-llm build command to build a model
artifact.
Below is an example that produces an artifact that uses 4-way tensor
parallelism and will save the compiled artifact into the ./Llama-3.1-8B-Instruct directory.
furiosa-llm build ./quantized_model ./Output-Llama-3.1-8B-Instruct \
-tp 4 \
--max-seq-len-to-capture 1024 \
--num-pipeline-builder-workers 4 \
--num-compile-workers 4
Tip
To achieve better performance or to run large language models on multiple NPUs, you can take advantage of model parallelism in Furiosa LLM. To learn more about model parallelism, please refer to the Model Parallelism section.
Deploying Model Artifacts#
Once you have a model artifact, you can copy and reuse it on any machine with a Furiosa NPU and Furiosa LLM installed. To transfer a model artifact:
Compress the model artifact directory using your preferred compression tool.
Copy the file to the target host.
Uncompress it on the target machine.
Run the model using either the LLM class or the OpenAI-Compatible Server.
For quick examples of loading and running model artifacts, refer to the Quick Start with Furiosa LLM section.
Current Limitations#
ArtifactBuildercurrently supports contexts lengths of up to 8k tokens only, even though Furiosa LLM supports up to 32k. FuriosaAI provides pre-built artifacts with higher context lengths for selected models. This limitation will be removed in the 2025.1 release.The current version of ArtifactBuilder requires models quantized by
QuantizerForCausalLM. The 2025.2 release will allow BF16 models to run on Furiosa LLM without the calibration and quantization steps.